
Understanding the Power Law Distribution

Ready to transform your data strategy with cutting-edge solutions?
Check out the below post I found on LinkedIn :

What caught my attention is the statement highlighted in Yellow. Following questions hit me almost instantly :
1. What events in the real world follow normal distribution?
2. If Content hits (read virality) doesn't follow normal distribution then which "one" does it follow?
3. What other kinds of statistical distributions exist and their real world use cases?
Let's try to answer the above questions in this blog.
Why Content Success Doesn't Follow a Normal Distribution?
Normal Distribution Basics: In a normal distribution, data points cluster around a mean (average) value with symmetrical tails on both sides. This kind of distribution is common in traits like human height or IQ, where most values are close to the mean and extreme values are rare.
Content Engagement Patterns: In content marketing, engagement patterns are different. Rather than clustering around an "average level of success," we often see that a small percentage of content pieces drive the majority of engagement and traffic. This pattern aligns with the Pareto Principle, or the 80/20 rule, where roughly 20% of content generates 80% of results.
Power-Law Distribution: Instead of a normal curve, content hits tend to follow a power-law distribution, which has a "long tail." This means that while a few pieces of content (like viral posts or hit videos) perform exceptionally well, the majority of content sees only modest engagement. In the LinkedIn post's case, a single video attracted 40% of total subscribers—a huge outlier compared to typical performance.
Examples of Outliers in Content and Media :
Social Media Posts: On platforms like Twitter or Instagram, a small number of posts might go viral, reaching millions, while the vast majority receive minimal engagement. For instance, a single tweet might gather hundreds of thousands of likes and retweets, while most tweets by the same user barely reach a fraction of that.
Blog Traffic: In a blog with hundreds of posts, it’s often observed that only a handful of “pillar” articles drive the bulk of traffic. These outlier articles often rank well on search engines or resonate uniquely with readers, creating a disproportionately large impact compared to the majority of posts.
E-commerce Products: A small percentage of products in an e-commerce store may generate most of the sales and revenue, while many products see little to no purchases. This is why companies focus on identifying and promoting bestsellers.
Fundamentals of Power Law Distribution :

In practical terms, power-law distributions describe situations where:
A few items have very high values (e.g., a few videos go viral).
Many items have low or moderate values (e.g., most videos get average or low views).
Real world phenomenon following the Power Law Distribution :
City Sizes: In most countries, a few cities (like New York or Mumbai) have very large populations, while the majority of cities are much smaller.
Wealth Distribution: A small percentage of people hold a large portion of global wealth, while most people have moderate or low wealth.
Website Traffic: A handful of websites (like Google and YouTube) get most of the traffic, while millions of sites receive only a fraction.
Word Frequencies: In any language, a few words are used very frequently, while many words are rarely used.
Common distributions in Nature :

Here's a visual comparison of the different distributions:
Power-Law Distribution (Top Left): Notice how it has a long tail on the right, meaning that high values are possible but rare. This type of distribution is common in phenomena with outliers, like content virality, where a few pieces achieve massive reach, while most remain low.
Poisson Distribution (Top Right): It clusters around a central value (in this case, around 10 events) and quickly drops off. It's suited for events that occur randomly over a fixed interval, like the number of customers arriving in a store per hour.
Binomial Distribution (Bottom Left): The probability of different numbers of successes in a series of trials (here, with n=50 and p=0.2) forms a distribution similar to Poisson but is bounded by the total number of trials, unlike the unbounded nature of Power-Law.
Normal Distribution (Bottom Right): Symmetrical and bell-shaped, with most values clustering around the mean. This distribution is common in traits like human height, where extremes are rare and values are concentrated around an average.
The Power-Law Distribution stands out due to its asymmetry and long tail, making it ideal for modeling situations with a few dominant outliers, like viral content or wealth distribution. This highlights why certain events are not well-explained by traditional distributions like Poisson or Normal.
Ready to Experience the Future of Data?
You Might Also Like
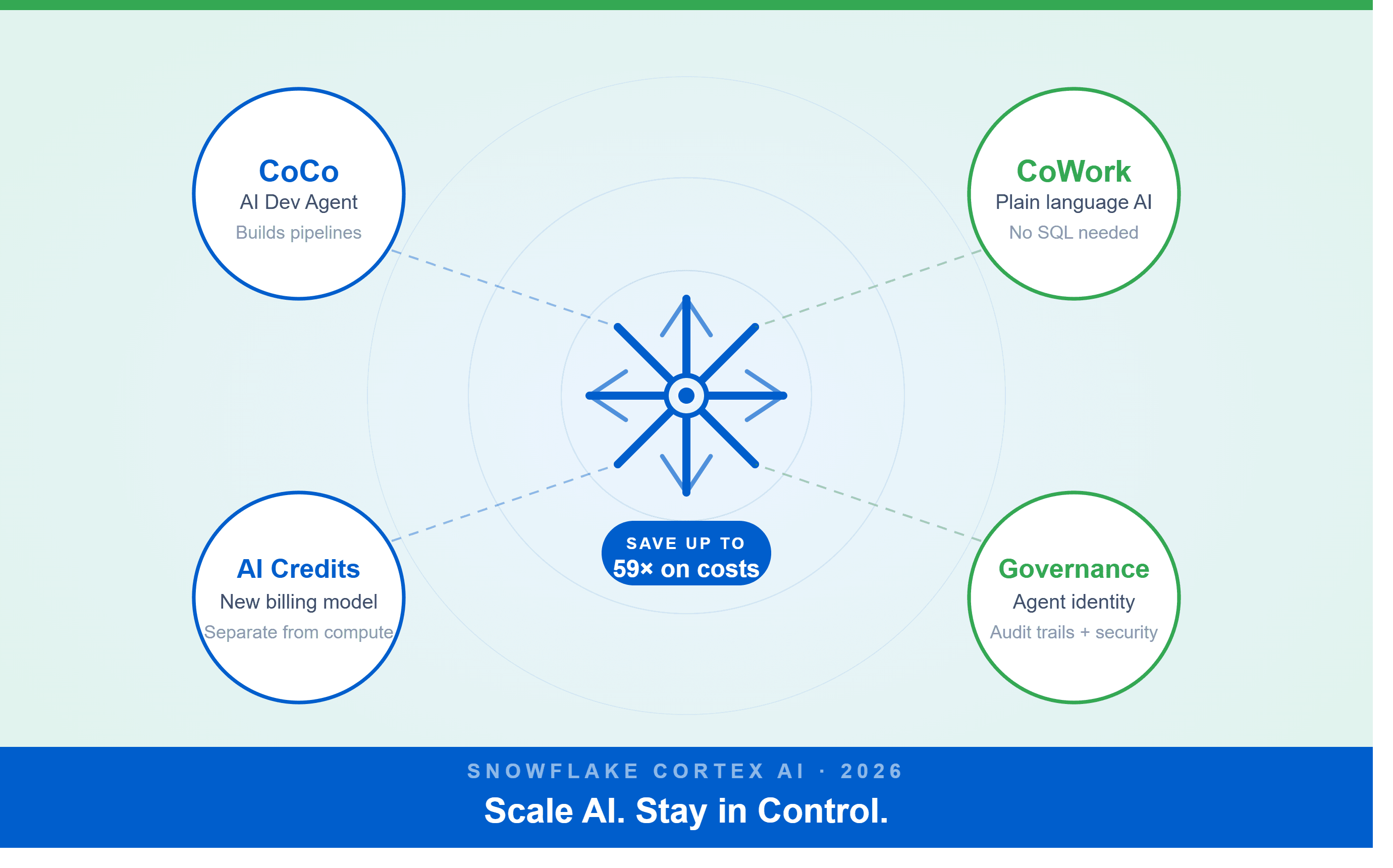
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
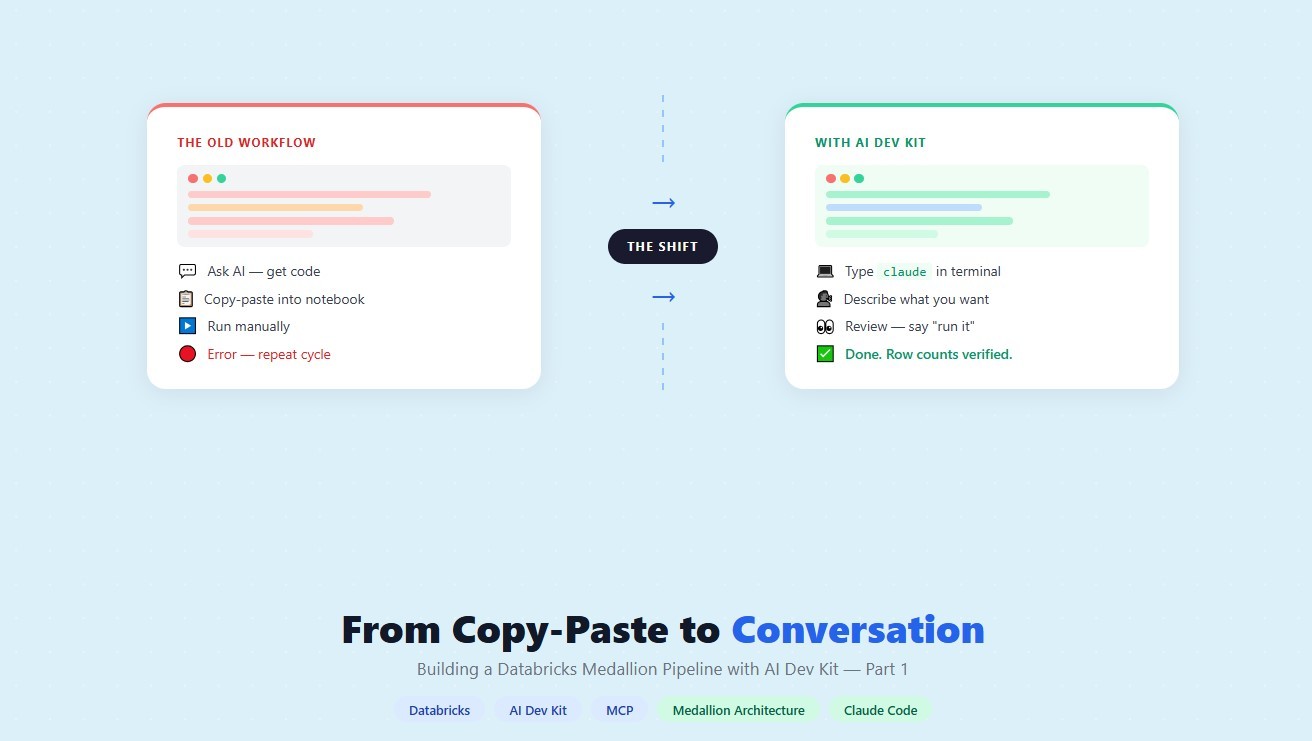
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
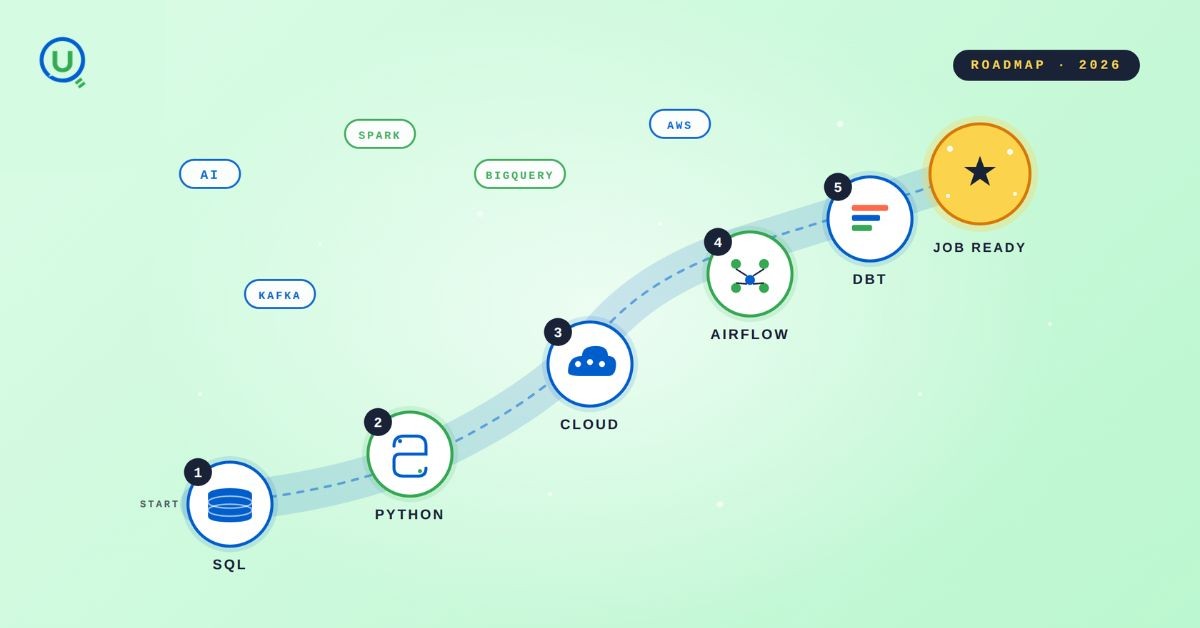
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.
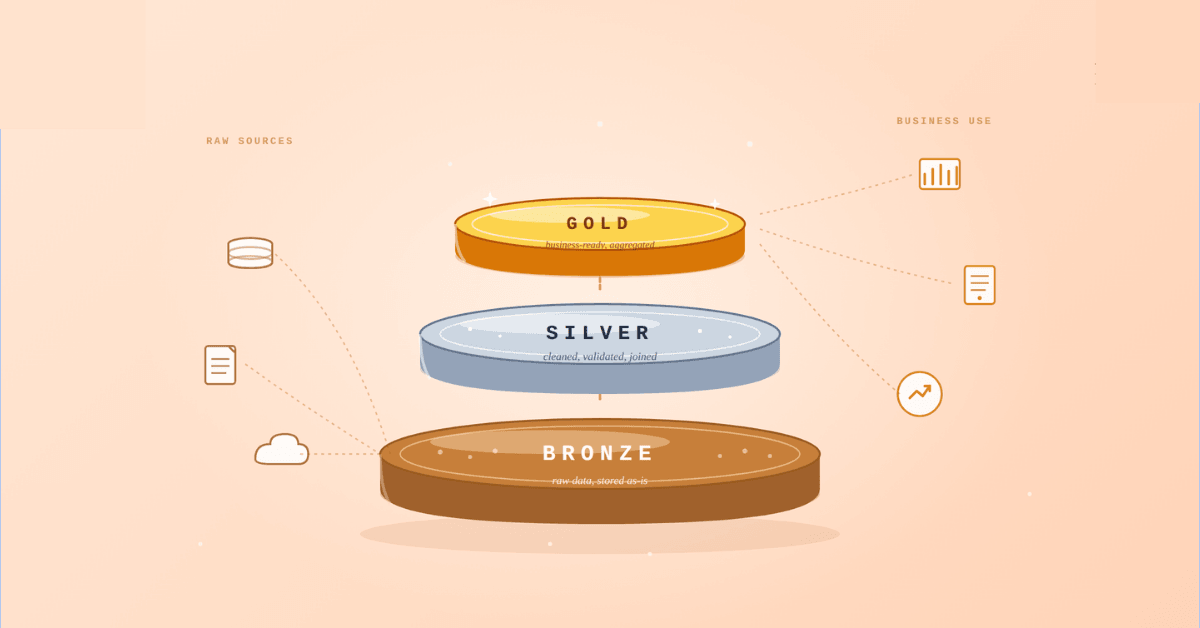
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications